Supplementary Material for: Soundscape Perception Indices (SPI)
Authors
Affiliation
Andrew Mitchell
University College London
Francesco Aletta
University College London
Published
November 11, 2024
Abstract
This document provides additional detail for the multi-objective optimization method of deriving Soundscape Perception Indices (SPI) from soundscape data presented in Section IV.B.1 of Soundscape Perception Indices (SPI): Developing context-dependent single value scores of multidimensional soundscape perceptual quality
The method is based on the optimization of a set of objective functions that are designed to capture the most important aspects of soundscape perception. The optimization is performed using a genetic algorithm, which is a stochastic optimization method that is well-suited to the multi-objective optimization problem of deriving SPI targets.
Role of a priori rankings in target definition
The core challenge in developing a reference SPI target is determining what constitutes an “ideal” soundscape perception distribution for a given context. While we can directly specify MSN parameters to create bespoke targets based on theoretical expectations or design goals, developing empirically-grounded reference targets requires a more systematic approach.
The a priori ranking serves as a bridge between existing knowledge about soundscape quality and the mathematical framework of the SPI. By starting with a ranking of soundscapes whose relative quality has been assessed through some external measure (in this demonstration, mean SSS01 scores, though other metrics could be used), we can use optimization techniques to derive MSN parameters that:
When used as an SPI target, produce scores that result in the same ranking order
Generate high SPI scores for the highly-ranked soundscapes
Define a distribution in the circumplex space that captures the perceptual characteristics common to high-quality soundscapes in this context
This approach allows us to work backwards from known good (and poor) examples to define what the target distribution should look like. For instance, if we know that location A has a better soundscape than location B for our purposes, the optimal target distribution should result in location A receiving a higher SPI score than location B.
In [1]:
# Import librariesimport warningsfrom pathlib import Pathimport numpy as npimport pandas as pdimport soundscapy as sspyfrom soundscapy.surveys.survey_utils import LANGUAGE_ANGLES, PAQ_IDSimport scripts.optimize_target as otfrom scripts.MultiSkewNorm import MultiSkewNormwarnings.filterwarnings("ignore")
/Users/mitch/Library/CloudStorage/OneDrive-UniversityCollegeLondon/_Fellowship/Papers - Drafts/J2401_JASA_SSID-Single-Index/.venv/lib/python3.11/site-packages/rpy2/robjects/numpy2ri.py:241: DeprecationWarning: The global conversion available with activate() is deprecated and will be removed in the next major release. Use a local converter.
warnings.warn('The global conversion available with activate() '
/Users/mitch/Library/CloudStorage/OneDrive-UniversityCollegeLondon/_Fellowship/Papers - Drafts/J2401_JASA_SSID-Single-Index/.venv/lib/python3.11/site-packages/rpy2/robjects/pandas2ri.py:368: DeprecationWarning: The global conversion available with activate() is deprecated and will be removed in the next major release. Use a local converter.
warnings.warn('The global conversion available with activate() '
Example using park soundscapes from the ISD
To demonstrate the method of deriving an SPI target from empirical data, we used a subset of locations from the International Soundscape Database (ISD) (Mitchell et al., 2024) that were classified as parks or park-like spaces.
In [2]:
# Load latest ISD datasetdata = sspy.isd.load()data, excl_data = sspy.isd.validate(data)data = data.query("Language != 'cmn'")# Exclude RegentsParkJapan outliers (the below code resulted in the `excl_id` list)# excl_id = list(data.query(# "LocationID == 'RegentsParkJapan'"# ).query("ISOEventful > 0.72 | ISOEventful < -0.5").index)# Excluded RegentsParkFields outliers# excl_id = excl_id + list(data.query(# "LocationID == 'RegentsParkFields' and ISOPleasant < 0").index) # Helicoptersexcl_id = [652, 706, 548, 550, 551, 553, 569, 580, 609, 618, 623, 636, 643]data.drop(excl_id, inplace=True)# Calculate ISOPleasant and ISOEventful# Here we use the adjusted angles from Aletta et al. (2024) for each language included.for i, row in data.iterrows(): lang = row["Language"] angles = LANGUAGE_ANGLES[lang] iso_pl, iso_ev = ( sspy.surveys.processing._adj_iso_pl(row[PAQ_IDS], angles, scale=4), sspy.surveys.processing._adj_iso_ev(row[PAQ_IDS], angles, scale=4), ) data.loc[i, "ISOPleasant"] = iso_pl data.loc[i, "ISOEventful"] = iso_ev
The following locations were identified as parks and included:
In [3]:
# Separate out parksparks = ["RegentsParkFields","RegentsParkJapan","Noorderplantsoen","StPaulsCross","MiradorSanNicolas","RussellSq","Noorderplantsoen","MonumentoGaribaldi","CampoPrincipe",]park_data = data.query("LocationID in @parks")
An initial ranking of these locations was created based on their mean SSS01 scores (overall soundscape quality rating) from the survey responses in the ISD:
In [4]:
# Creating a somewhat arbitrary ranking of parksrank_on ="sss01"park_quality = pd.DataFrame( park_data.groupby("LocationID")[rank_on].mean().sort_values(ascending=False))park_quality["Rank"] =range(1, len(park_quality) +1)park_quality.head(10)
sss01
Rank
LocationID
RegentsParkJapan
4.617978
1
RegentsParkFields
4.467290
2
CampoPrincipe
4.345455
3
MonumentoGaribaldi
4.156250
4
RussellSq
4.020548
5
MiradorSanNicolas
3.964286
6
StPaulsCross
3.803030
7
Noorderplantsoen
2.412371
8
It’s important to note that, as stated in the main paper, this ranking is used primarily to demonstrate the methodology of deriving a target from a pre-existing ranking. While based on real survey data, this particular ranking should not be considered a definitive assessment of these spaces’ soundscape quality, due to the mono-dimensional nature of the SSS01 question. To develop a true reference target, the ranking would need to be arrived at through more rigorous empirical methods such as paired-choice comparisons or other experimental protocols. The purpose of using this ranking is twofold:
To demonstrate that the SPI framework can incorporate existing knowledge or preferences about soundscape quality into the target definition process
To show how multi-objective optimization can be used to derive MSN parameters that produce an SPI scoring system aligned with predetermined quality assessments
Optimisation Task Formulation
SPI Targets
To set up the optimisation task, we first need to express the parameter space and any constraints. The SPI target is a set of parameters that define the distribution of soundscape perception in a given soundscape. The target is defined as a multivariate skew-normal (MSN) distribution with the following parameters:
is the location parameter, which defines the mean of the distribution in the x and y dimensions. The location parameter is constrained to lie within the range \(-1 \leq \xi \leq 1\) to ensure that the target distribution is within the range of possible soundscape perceptions (i.e. within the circumplex).
is the covariance matrix, which defines the shape of the distribution. The covariance matrix must be symmetric \((cov(x,y) = cov(y,x))\) and positive definite to ensure that the distribution is well-defined. These requirements arise from the mathematical properties needed for a valid probability distribution. The variance and covariance parameters are constrained within realistic ranges based on observed soundscape distributions in the ISD.
is the skewness parameter, which defines the skewness of the distribution in the x and y dimensions. The skewness parameter range is chosen to allow for meaningful asymmetry while preventing extreme or unrealistic distributions.
Objective Functions
Our optimization problem requires carefully chosen objective functions that can effectively translate an ordinal ranking of soundscape quality into meaningful MSN parameters. Two competing objectives are defined to ensure the resulting target distribution is both valid and useful:
Rank Correlation Objective:
\[
f_1 = r(ranks_{quality}, ranks_{target})
\]
where \(r\) is the Spearman rank correlation coefficient. This objective ensures the derived target preserves the original quality ordering of the soundscapes. A high rank correlation indicates that when the target is used to calculate SPI scores for each location, those scores produce a similar ranking to our a priori assessment.
where \(m\) is the number of locations and \(rank_i\) is the a priori rank of location \(i\). This objective addresses several important aspects:
It ensures the target produces meaningfully scaled scores, not just correct rankings
The weighting (\(\frac{1}{rank_i}\)) prioritizes high SPI scores for locations ranked as high quality
It prevents solutions that achieve the correct ranking but with compressed or arbitrary score ranges
It helps anchor the target distribution in regions of the circumplex space associated with positive soundscape experiences for this context.
The two objectives work together to resolve key challenges in target derivation:
Rank correlation alone could produce valid but impractical targets (e.g., targets that correctly rank soundscapes but give very low scores to all locations)
Weighted scores alone might maximize scores without preserving the relative quality relationships
Together, they ensure the target both discriminates between soundscape quality levels and produces scores that reflect absolute quality judgments
In pymoo, each objective function is supposed to be minimized. Therefore, in the code implementation these objectives are negated to convert them into minimization problems. For each step in the algorithm with a given trial set of parameters, a target distribution will be produced, the SPI for each test location assessed according to the protocol described in the full paper, and the resulting set of SPI scores and ranking will be scored using the objective functions.
The optimization problem described above presents significant computational challenges. A naive approach might involve systematically sampling the parameter space through a grid search, evaluating both objective functions at each point. However, with seven parameters to optimize and the need for fine granularity to capture optimal solutions, the search space becomes prohibitively large. Additionally, the requirement that the covariance matrix must be positive definite creates irregular boundaries in the parameter space that make systematic searching impractical.
We therefore employ the Non-dominated Sorting Genetic Algorithm II (NSGA-II), which uses principles from evolutionary computation to search the parameter space efficiently. The algorithm maintains a population of potential solutions, where each solution represents a complete set of MSN parameters (ξ, Ω, α). In our implementation, we use a population of 150 solutions, initialized randomly within the parameter constraints defined in Section 2.1.
The algorithm proceeds iteratively, with each iteration (or generation) involving four main steps:
First, the algorithm evaluates both objective functions (rank correlation and weighted scores) for each solution in the current population. Since we have multiple objectives, there is rarely a single “best” solution. Instead, solutions are ranked based on dominance - solution A dominates solution B if it performs at least as well on both objectives and better on at least one. Solutions that are not dominated by any other solutions form the first front, those only dominated by solutions in the first front form the second front, and so on.
Second, to maintain diversity in the population, the algorithm calculates a “crowding distance” for each solution. This distance measures how close a solution is to its neighbors in terms of objective function values. Solutions that are more isolated (have larger crowding distances) are preferred to prevent the population from clustering too tightly around local optima.
Third, new solutions are generated through crossover and mutation operations. Crossover combines parameters from two parent solutions to create offspring solutions, while mutation introduces small random changes to parameter values. These operations are controlled to ensure new solutions remain within the valid parameter ranges and covariance matrix constraints.
Finally, the algorithm selects solutions to form the next generation’s population. Solutions are chosen primarily based on their front ranking (lower/better fronts are preferred), and within the same front, solutions with larger crowding distances are preferred. This selection process ensures both convergence toward better solutions and maintenance of diversity in the population.
The algorithm runs for 100 generations, producing a set of solutions known as the Pareto front - solutions representing different trade-offs between our two objectives. From this front, we select a final solution using an Augmented Scalarizing Function with weights [0.48, 0.52], indicating a slight preference for the weighted score objective while maintaining strong rank correlation.
Park Quality optimization
In [7]:
# initialize the thread pool and create the runnermp = pathos.helpers.mpn_process =12pool = mp.Pool(n_process)runner = StarmapParallelization(pool.starmap)# Initialize the NSGA problempark_problem = MyProblem( data=park_data, ranking=park_quality.sort_index()["Rank"], elementwise_runner=runner)# Run the optimizationpark_res = minimize( park_problem, algorithm, termination, seed=42, save_history=True, verbose=True)pool.close()park_F = park_res.Fpark_X = park_res.X
# Record a video of the optimization processweights = np.array([0.5, 0.5])decomp = ASF()with Recorder(Video("figures/park_nsga2.mp4")) as rec:for entry in park_res.history:# Get the approximated ideal and nadir points approx_ideal = park_res.F.min(axis=0) approx_nadir = park_res.F.max(axis=0)# Normalize the obtained front nF = (entry.pop.get("F") - approx_ideal) / (approx_nadir - approx_ideal) park_I = decomp(nF, weights).argmin() sc = Scatter(title="Generation: %s"% entry.n_gen) sc.add(entry.pop.get("F")) sc.add(entry.pop.get("F")[park_I], color="red", s=30) sc.do() rec.record()with Recorder(Video("figures/park_nsga2_sspy.mp4")) as rec:for entry in park_res.history:# Get the approximated ideal and nadir points approx_ideal = park_res.F.min(axis=0) approx_nadir = park_res.F.max(axis=0)# Normalize the obtained front nF = (entry.pop.get("F") - approx_ideal) / (approx_nadir - approx_ideal) park_I = decomp(nF, weights).argmin() park_X = entry.pop.get("X")[park_I] park_tgt = MultiSkewNorm() park_tgt.define_dp( np.array([park_X[0], park_X[1]]), np.array([[park_X[2], park_X[4]], [park_X[4], park_X[3]]]), np.array([park_X[5], park_X[6]]), ) park_tgt.sample() ss = sspy.plotting.density_plot( data=pd.DataFrame( {"ISOPleasant": park_tgt.sample_data[:, 0],"ISOEventful": park_tgt.sample_data[:, 1], } ), title="Generation: %s"% entry.n_gen, ) rec.record()
Selecting the best solution
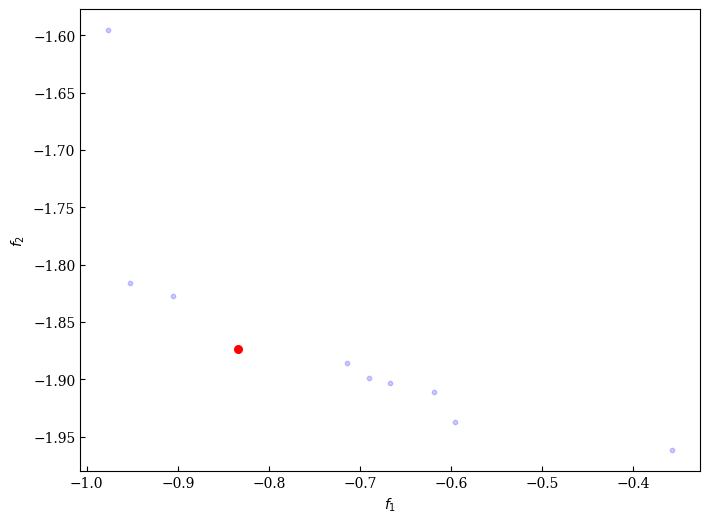
The optimization produces a set of non-dominated solutions forming a Pareto front, where each point represents a different set of MSN parameters. However, selecting a single solution from this front requires careful consideration of the relative scales of our objective functions. The rank correlation objective (f₁) typically ranges from -1 to 1, while the weighted SPI score objective (f₂) can range from 0 to 100. This difference in scales means we cannot directly compare or combine these objectives without normalization.
To address this scale disparity, we first approximate the boundaries of our objective space using the best and worst values found for each objective during the optimization process. These boundary points (called the ideal and nadir points) allow us to normalize both objectives to a common scale ranging from 0 to 1. The normalized front maintains the same trade-off relationships between solutions but allows for fair weighting in the final selection process.
To select a single solution from this normalized front, we employ the Augmented Scalarization Function (ASF). The ASF combines multiple objectives into a single metric while maintaining Pareto optimality. We assign equal weights [0.5, 0.5] to both objectives, indicating no preference between ranking accuracy and score distribution. The ASF also includes a small augmentation term that ensures we select solutions that perform reasonably well on both objectives rather than extremely well on one but poorly on the other.
The solution minimizing the ASF yields the following MSN parameters:
In [9]:
from pymoo.decomposition.asf import ASF# Get the approximated ideal and nadir pointsapprox_ideal = park_res.F.min(axis=0)approx_nadir = park_res.F.max(axis=0)# Normalize the obtained frontnF = (park_res.F - approx_ideal) / (approx_nadir - approx_ideal)weights = np.array([0.4, 0.5])decomp = ASF()park_I = decomp(nF, weights).argmin()# print("Best regarding decomposition: Point %s - %s" % (park_I, park_res.F[park_I]))print(park_tgt.summary())
Fitted from direct parameters.
Direct Parameters:
xi: [0.637 0.403]
omega: [[0.131 0.018]
[0.018 0.262]]
alpha: [ 2.502 -11.987]
None
None
These parameters define a target distribution that achieves a rank correlation of 0.714 with the a priori ranking while maintaining meaningfully scaled SPI scores. The location parameters (\(\xi\)) place the distribution’s center in the vibrant quadrant of the circumplex, while the covariance matrix (\(\Omega\)) describes a moderately spread distribution with positive correlation between pleasantness and eventfulness. The skewness parameters (\(\alpha\)) indicate strong negative skew, particularly in the eventfulness dimension, suggesting the target favors soundscapes that avoid high eventfulness while maintaining moderate to high pleasantness.
Resulting Target Distribution
Figure 1 (a) shows the Pareto front obtained from the optimization process, where each point represents a different set of MSN parameters and their corresponding objective function values. The x-axis shows the negative rank correlation (-f₁) and the y-axis shows the negative weighted SPI score (-f₂). The selected solution using the ASF with equal weights is highlighted in red. The spread of solutions along the front illustrates the fundamental trade-off between achieving perfect rank correlation and maximizing SPI scores.
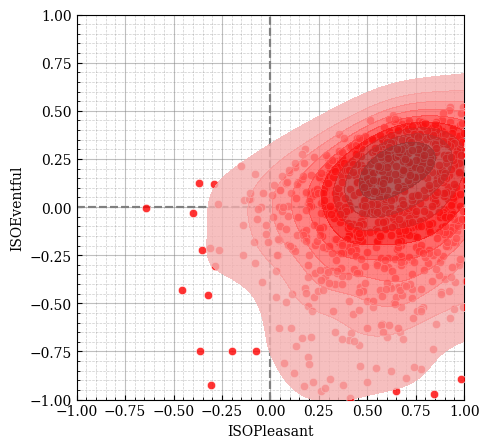
Figure 1 (b) shows the resulting target distribution in the soundscape circumplex model, sampled from the MSN parameters of our selected solution. The distribution is centered in the pleasant-eventful quadrant but shows clear asymmetry, with a longer tail extending into the calm quadrant. This shape suggests that while the target generally favors pleasant soundscapes, it is more tolerant of variation in eventfulness than in pleasantness. The moderate spread of the distribution indicates that the target allows for some natural variation in perception while still maintaining clear preferences for certain regions of the circumplex.
Together, these visualizations demonstrate both the optimization process (through the Pareto front) and its outcome (through the target distribution). The selected solution represents a balanced compromise between maintaining ranking accuracy and producing meaningful score distributions, while the resulting target distribution aligns with theoretical expectations about high-quality park soundscapes.